| Question | Randomization | Bootstrapping | Mathematical models |
|---|---|---|---|
| What does it do? | Shuffles the explanatory variable to mimic the natural variability found in a randomized experiment | Resamples (with replacement) from the observed data to mimic the sampling variability found by collecting data from a population | Uses theory (primarily the Central Limit Theorem) to describe the hypothetical variability resulting from either repeated randomized experiments or random samples |
| What is the random process described? | Randomized experiment | Random sampling from a population | Randomized experiment or random sampling |
| What other random processes can be approximated? | Can also be used to describe random sampling in an observational model | Can also be used to describe random allocation in an experiment | Can also be used to describe random sampling in an observational model or random allocation in an experiment |
| What is it best for? | Hypothesis testing (can also be used for confidence intervals, but not covered in this text) | Confidence intervals (can also be used for bootstrap hypothesis testing for one proportion as well) | Quick analyses through, for example, calculating a Z score |
| What physical object represents the simulation process? | Shuffling cards | Pulling marbles from a bag with replacement | Not applicable |
15 Applications: Foundations
15.1 Recap: Foundations
In the foundations of inference chapters, we have provided three different methods for statistical inference. We will continue to build on all three of the methods throughout the text, and by the end, you should have an understanding of the similarities and differences between them. Meanwhile, it is important to note that the methods are designed to mimic variability with data, and we know that variability can come from different sources (e.g., random sampling vs. random allocation, see Figure 2.8). In Table 15.1, we have summarized some of the ways the inferential procedures feature specific sources of variability. We hope that you refer back to the table often as you dive more deeply into inferential ideas in future chapters.
You might have noticed that the word distribution is used throughout this part (and will continue to be used in future chapters). A distribution always describes variability, but sometimes it is worth reflecting on what is varying. Typically the distribution either describes how the observations vary or how a statistic varies. But even when describing how a statistic varies, there is a further consideration with respect to the study design, e.g., does the statistic vary from random sample to random sample or does it vary from random allocation to random allocation? The methods presented in this text (and used in science generally) are typically used interchangeably across ideas of random samples or random allocations of the treatment. Often, the two different analysis methods will give equivalent conclusions. The most important thing to consider is how to contextualize the conclusion in terms of the problem. See Figure 2.8 to confirm that your conclusions are appropriate.
Below, we synthesize the different types of distributions discussed throughout the text. Reading through the different definitions and solidifying your understanding will help as you come across these distributions in future chapters and you can always return back here to refresh your understanding of the differences between the various distributions.
Distributions.
-
A data distribution describes the shape, center, and variability of the observed data.
This can also be referred to as the sample distribution but we’ll avoid that phrase as it sounds too much like sampling distribution, which is different.
-
A population distribution describes the shape, center, and variability of the entire population of data.
Except in very rare circumstances of very small, very well-defined populations, this is never observed.
-
A sampling distribution describes the shape, center, and variability of all possible values of a sample statistic from samples of a given sample size from a given population.
Since the population is never observed, it’s never possible to observe the true sampling distribution either. However, when certain conditions hold, the Central Limit Theorem tells us what the sampling distribution is.
-
A randomization distribution describes the shape, center, and variability of all possible values of a sample statistic from random allocations of the treatment variable.
We computationally generate the randomization distribution, though usually, it’s not feasible to generate the full distribution of all possible values of the sample statistic, so we instead generate a large number of them. Almost always, by randomly allocating the treatment variable, the randomization distribution describes the null hypothesis, i.e., it is centered at the null hypothesized value of the parameter.
-
A bootstrap distribution describes the shape, center, and variability of all possible values of a sample statistic from resamples of the observed data.
We computationally generate the bootstrap distribution, though usually, it’s not feasible to generate all possible resamples of the observed data, so we instead generate a large number of them. Since bootstrap distributions are generated by randomly resampling from the observed data, they are centered at the sample statistic. Bootstrap distributions are most often used for estimation, i.e., we base confidence intervals off of them.
15.2 Case study: Malaria vaccine
In this case study, we consider a new malaria vaccine called PfSPZ. In the malaria study, volunteer patients were randomized into one of two experiment groups: 14 patients received an experimental vaccine and 6 patients received a placebo vaccine. Nineteen weeks later, all 20 patients were exposed to a drug-sensitive strain of the malaria parasite; the motivation of using a drug-sensitive strain here is for ethical considerations, allowing any infections to be treated effectively.
The results are summarized in Table 15.2, where 9 of the 14 treatment patients remained free of signs of infection while all of the 6 patients in the control group showed some baseline signs of infection.
| Treatment | Infection | No infection | Total |
|---|---|---|---|
| placebo | 6 | 0 | 6 |
| vaccine | 5 | 9 | 14 |
| Total | 11 | 9 | 20 |
Is this an observational study or an experiment? What implications does the study type have on what can be inferred from the results?1
15.2.1 Variability within data
In this study, a smaller proportion of patients who received the vaccine showed signs of an infection (35.7% versus 100%). However, the sample is very small, and it is unclear whether the difference provides convincing evidence that the vaccine is effective.
Statisticians and data scientists are sometimes called upon to evaluate the strength of evidence. When looking at the rates of infection for patients in the two groups in this study, what comes to mind as we try to determine whether the data show convincing evidence of a real difference?
The observed infection rates (35.7% for the treatment group versus 100% for the control group) suggest the vaccine may be effective. However, we cannot be sure if the observed difference represents the vaccine’s efficacy or if there is no treatment effect and the observed difference is just from random chance. Generally there is a little bit of fluctuation in sample data, and we wouldn’t expect the sample proportions to be exactly equal, even if the truth was that the infection rates were independent of getting the vaccine. Additionally, with such small samples, perhaps it’s common to observe such large differences when we randomly split a group due to chance alone!
This example is a reminder that the observed outcomes in the data sample may not perfectly reflect the true relationships between variables since there is random noise. While the observed difference in rates of infection is large, the sample size for the study is small, making it unclear if this observed difference represents efficacy of the vaccine or whether it is simply due to chance. We label these two competing claims, \(H_0\) and \(H_A\):
\(H_0\): Independence model. The variables are independent. They have no relationship, and the observed difference between the proportion of patients who developed an infection in the two groups, 64.3%, was due to chance.
\(H_A\): Alternative model. The variables are not independent. The difference in infection rates of 64.3% was not due to chance. Here (because an experiment was done), if the difference in infection rate is not due to chance, it was the vaccine that affected the rate of infection.
What would it mean if the independence model, which says the vaccine had no influence on the rate of infection, is true? It would mean 11 patients were going to develop an infection no matter which group they were randomized into, and 9 patients would not develop an infection no matter which group they were randomized into. That is, if the vaccine did not affect the rate of infection, the difference in the infection rates was due to chance alone in how the patients were randomized.
Now consider the alternative model: infection rates were influenced by whether a patient received the vaccine or not. If this was true, and especially if this influence was substantial, we would expect to see some difference in the infection rates of patients in the groups.
We choose between these two competing claims by assessing if the data conflict so much with \(H_0\) that the independence model cannot be deemed reasonable. If this is the case, and the data support \(H_A,\) then we will reject the notion of independence and conclude the vaccine was effective.
15.2.2 Simulating the study
We’re going to implement simulation under the setting where we will pretend we know that the malaria vaccine being tested does not work. Ultimately, we want to understand if the large difference we observed in the data is common in these simulations that represent independence. If it is common, then maybe the difference we observed was purely due to chance. If it is very uncommon, then the possibility that the vaccine was helpful seems more plausible.
Table 15.2 shows that 11 patients developed infections and 9 did not. For our simulation, we will suppose the infections were independent of the vaccine and we were able to rewind back to when the researchers randomized the patients in the study. If we happened to randomize the patients differently, we may get a different result in this hypothetical world where the vaccine does not influence the infection. Let’s complete another randomization using a simulation.
In this simulation, we take 20 notecards to represent the 20 patients, where we write down “infection” on 11 cards and “no infection” on 9 cards. In this hypothetical world, we believe each patient that got an infection was going to get it regardless of which group they were in, so let’s see what happens if we randomly assign the patients to the treatment and control groups again. We thoroughly shuffle the notecards and deal 14 into a pile and 6 into a pile. Finally, we tabulate the results, which are shown in Table 15.3.
| treatment | placebo | vaccine | Total |
|---|---|---|---|
| infection | 4 | 7 | 11 |
| no infection | 2 | 7 | 9 |
| Total | 6 | 14 | 20 |
How does this compare to the observed 64.3% difference in the actual data?2
15.2.3 Independence between treatment and outcome
We computed one possible difference under the independence model in the previous Guided Practice, which represents one difference due to chance, assuming there is no vaccine effect. While in this first simulation, we physically dealt out notecards to represent the patients, it is more efficient to perform the simulation using a computer.
Repeating the simulation on a computer, we get another difference due to chance: \[ \frac{2}{6{}} - \frac{9}{14} = -0.310 \]
And another: \[ \frac{3}{6{}} - \frac{8}{14} = -0.071\]
And so on until we repeat the simulation enough times to create a distribution of differences that could have occurred if the null hypothesis was true.
Figure 15.1 shows a stacked plot of the differences found from 100 simulations, where each dot represents a simulated difference between the infection rates (control rate minus treatment rate).
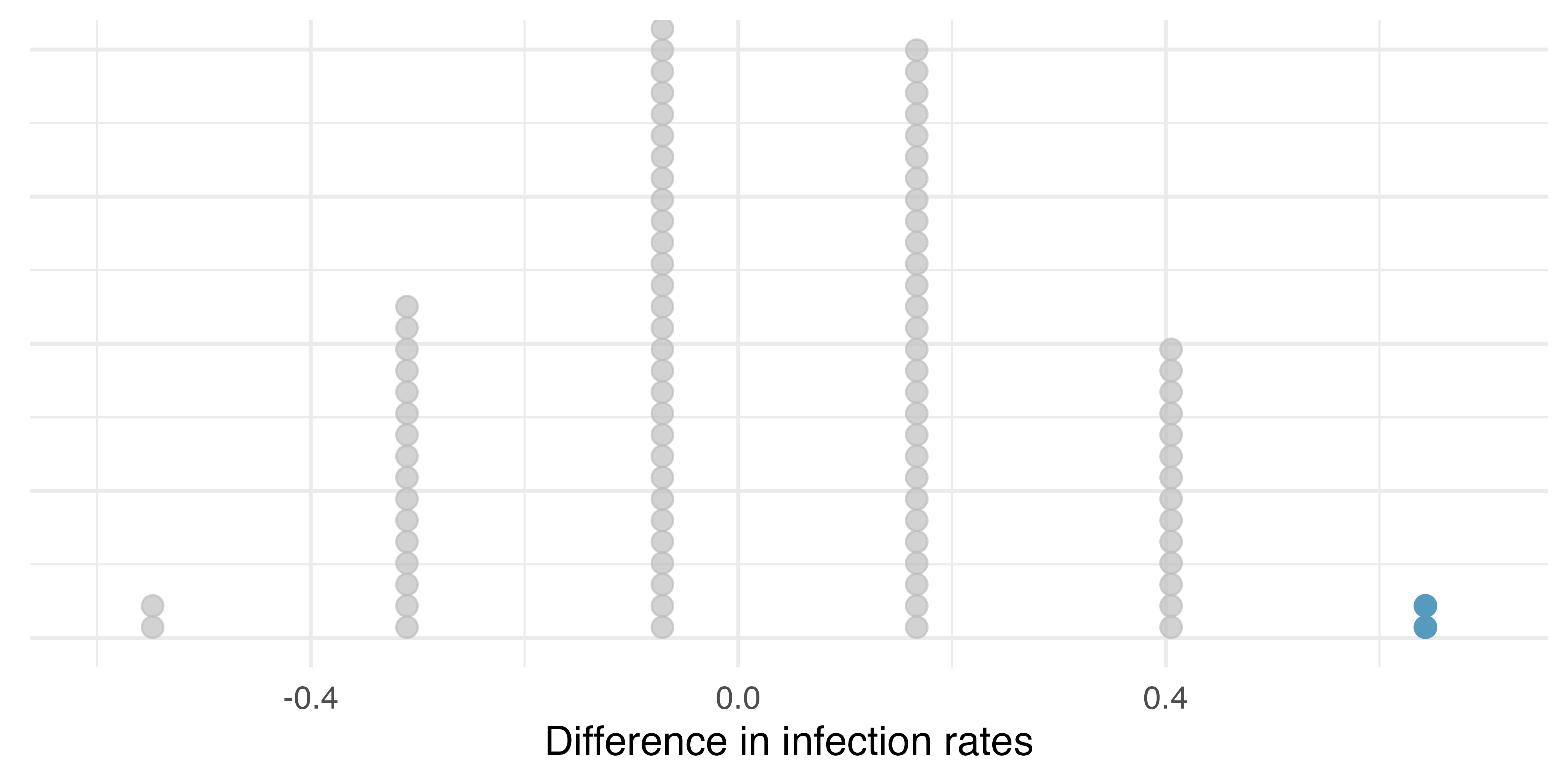
Note that the distribution of these simulated differences is centered around 0. We simulated these differences assuming that the independence model was true, and under this condition, we expect the difference to be near zero with some random fluctuation, where near is pretty generous in this case since the sample sizes are so small in this study.
How often would you observe a difference of at least 64.3% (0.643) according to Figure 15.1? Often, sometimes, rarely, or never?
It appears that a difference of at least 64.3% due to chance alone would only happen about 2% of the time according to Figure 15.1. Such a low probability indicates a rare event.
The difference of 64.3% being a rare event suggests two possible interpretations of the results of the study:
\(H_0\): Independence model. The vaccine has no effect on infection rate, and we just happened to observe a difference that would only occur on a rare occasion.
\(H_A\): Alternative model. The vaccine has an effect on infection rate, and the difference we observed was actually due to the vaccine being effective at combating malaria, which explains the large difference of 64.3%.
Based on the simulations, we have two options. (1) We conclude that the study results do not provide strong evidence against the independence model. That is, we do not have sufficiently strong evidence to conclude the vaccine had an effect in this clinical setting. (2) We conclude the evidence is sufficiently strong to reject \(H_0\) and assert that the vaccine was useful. When we conduct formal studies, usually we reject the notion that we just happened to observe a rare event. So in the vaccine case, we reject the independence model in favor of the alternative. That is, we are concluding the data provide strong evidence that the vaccine provides some protection against malaria in this clinical setting.
One field of statistics, statistical inference, is built on evaluating whether such differences are due to chance. In statistical inference, data scientists evaluate which model is most reasonable given the data. Errors do occur, just like rare events, and we might choose the wrong model. While we do not always choose correctly, statistical inference gives us tools to control and evaluate how often decision errors occur.
15.3 Interactive R tutorials
Navigate the concepts you’ve learned in this part in R using the following self-paced tutorials. All you need is your browser to get started!
You can also access the full list of tutorials supporting this book here.
15.4 R labs
Further apply the concepts you’ve learned in this part in R with computational labs that walk you through a data analysis case study.
You can also access the full list of labs supporting this book here.
The study is an experiment, as patients were randomly assigned an experiment group. Since this is an experiment, the results can be used to evaluate a causal relationship between the malaria vaccine and whether patients showed signs of an infection.↩︎
\(4 / 6 - 7 / 14 = 0.167\) or about 16.7% in favor of the vaccine. This difference due to chance is much smaller than the difference observed in the actual groups.↩︎